分布式学习
分布式学习
起源
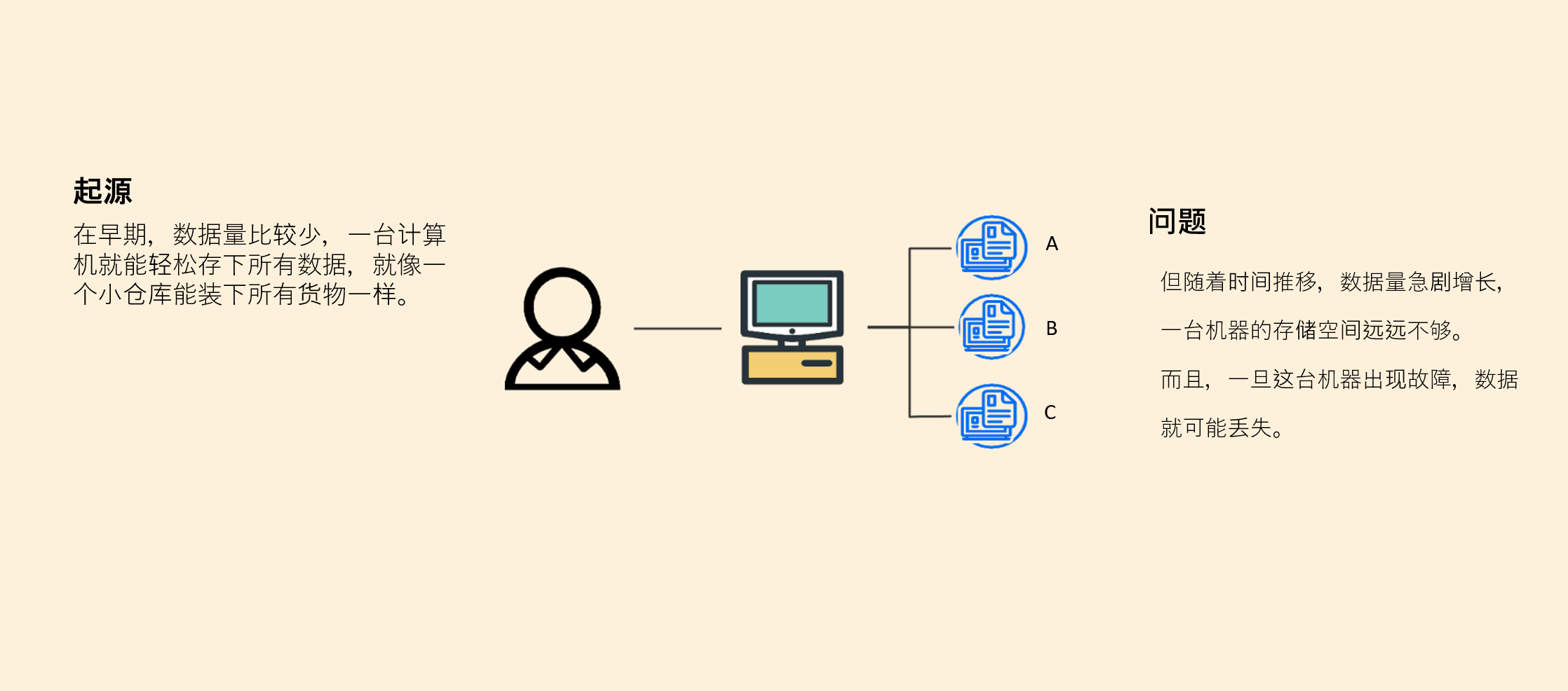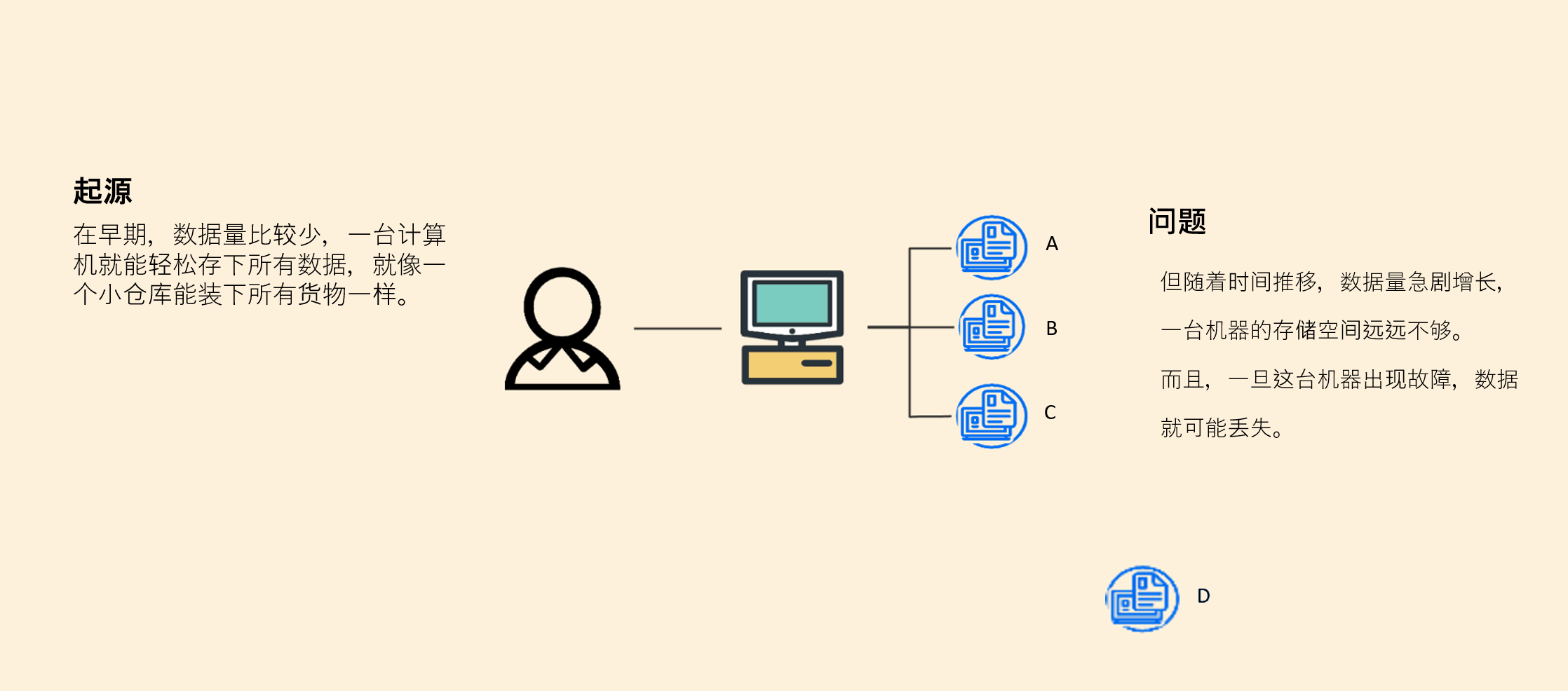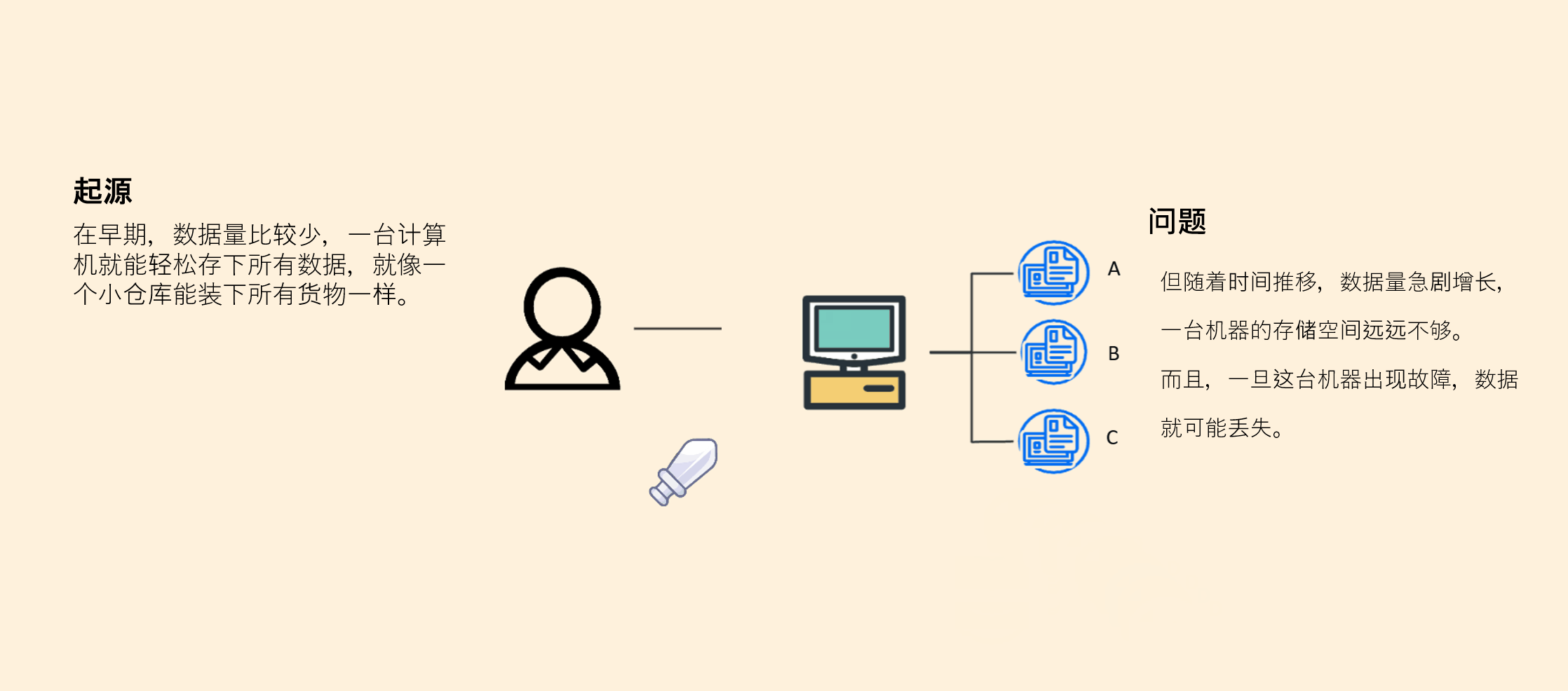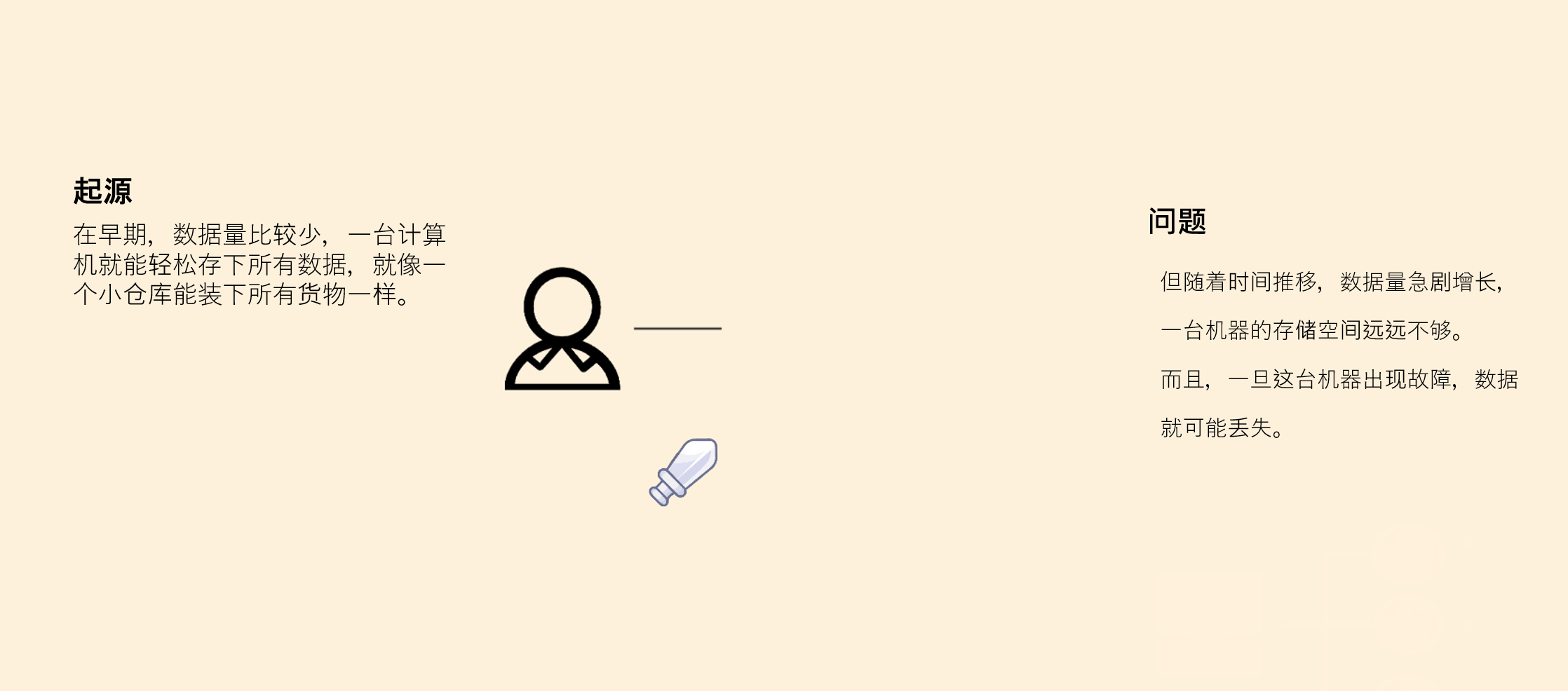
在早期,数据量比较少,一台计算机就能轻松存下所有数据,就像一个小仓库能装下所有货物一样。
问题1:
但随着时间推移,数据量急剧增长,一台机器的存储空间远远不够,就好比小仓库装不下越来越多的货物了。而且,一旦这台机器出现故障,数据就可能丢失,这就像小仓库着火了,里面的货物都没了。
解决1:
为了解决这个问题,人们想到用多台机器来存储数据,这样可以拓展存储空间,就像把货物分散存放在多个小仓库里。同时,为了防止某台机器故障导致数据丢失,还会对数据进行备份,就像给重要货物多准备几份副本存放在不同的小仓库。
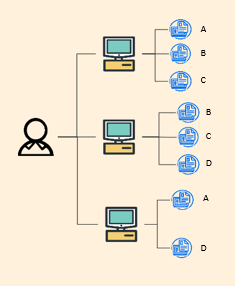
问题2
虽然用多台机器存储数据解决了空间和容错问题,但手动管理这些机器和数据变得非常麻烦。比如,要备份数据时,得一台机器一台机器地操作;查找数据时,也得在不同机器中挨个寻找。就像要从多个小仓库里找一件货物,得一个个仓库去翻,效率很低。
解决2
没有什么是加一层中间层不能解决的。我们找到了开源分布软件hadoop,其核心的HDFS(Hadoop Flie System) 就像一个智能的仓库管理员,它在底层实现了机器的拓展和数据的备份。它会自动把大文件拆分成小块,分散存放在不同的机器上,并且会自动管理数据的副本。同时,它还提供了方便的数据查找功能,用户只需要告诉它要找什么数据,它就能快速定位到数据所在的机器,就像仓库管理员能快速告诉你货物存放在哪个小仓库一样。
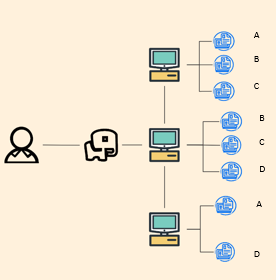
问题3
但当要对这些数据进行处理时,比如进行数据统计分析,用户还得自己编写复杂的代码(如 MapReduce 程序)来对数据进行分片和处理。而且,不同的处理任务可能会同时竞争集群的资源,导致资源分配不合理,效率低下。比如分别统计AB数据和CD数据,三个计算机如果顺序执行就效率太低下了,如果并行又有可能抢着要同一个cpu,同一片内存。
解决3
没有什么是加一层中间层不能解决的,如果有,那就再加一层。为了解决这个问题,Yarn(Yet Another Resource Negotiator)出现了。Yarn 就像一个仓库的调度中心,它负责管理和调度集群中的计算资源。它会根据不同任务的需求,合理地分配 CPU、内存等资源,确保每个任务都能高效地运行。同时,它还支持多种计算框架,不同的计算任务都可以在 Yarn 的调度下使用集群资源。
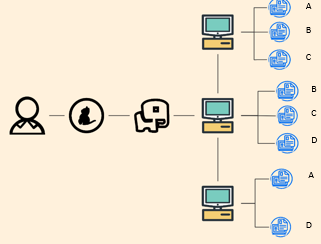
问题4
但是问题又来了,就算这样,具体数据的处理逻辑仍然需要我们自己写代码处理,对于文件要怎么map分片,又怎么reduce聚合。编写复杂的 MapReduce 代码还是太累了。有没有办法解决呢?
解决4
没有什么是加一层中间层不能解决的,如果有,那就再加一层。Hive 就是为了解决这个问题而诞生的。Hive 类似一个翻译官,它允许用户使用类似 SQL 的语言(HiveQL)来查询和分析存储在 HDFS 中的数据。Hive 会把用户输入的 HiveQL 语句翻译成 MapReduce 或其他计算任务,然后提交给 Yarn 进行调度执行。这样,用户就不需要编写复杂的代码,只需要用熟悉的 SQL 语言就能完成数据处理任务。
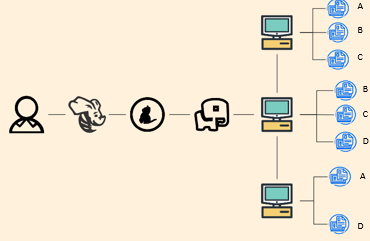
实验
使用虚拟机模拟分布式存储与计算以学习和体会分布式数据的存储和分析。实验将模拟一些数据文件数据存入多个不同的虚拟机,通过hadoop统一管理数据,通过hive进行数据分析和处理。
实验记录
环境配置
1. 物理机中(win11为例)
网络配置
让我们的几台虚拟机处于同一内网,允许互相通讯。
搜索:网络连接
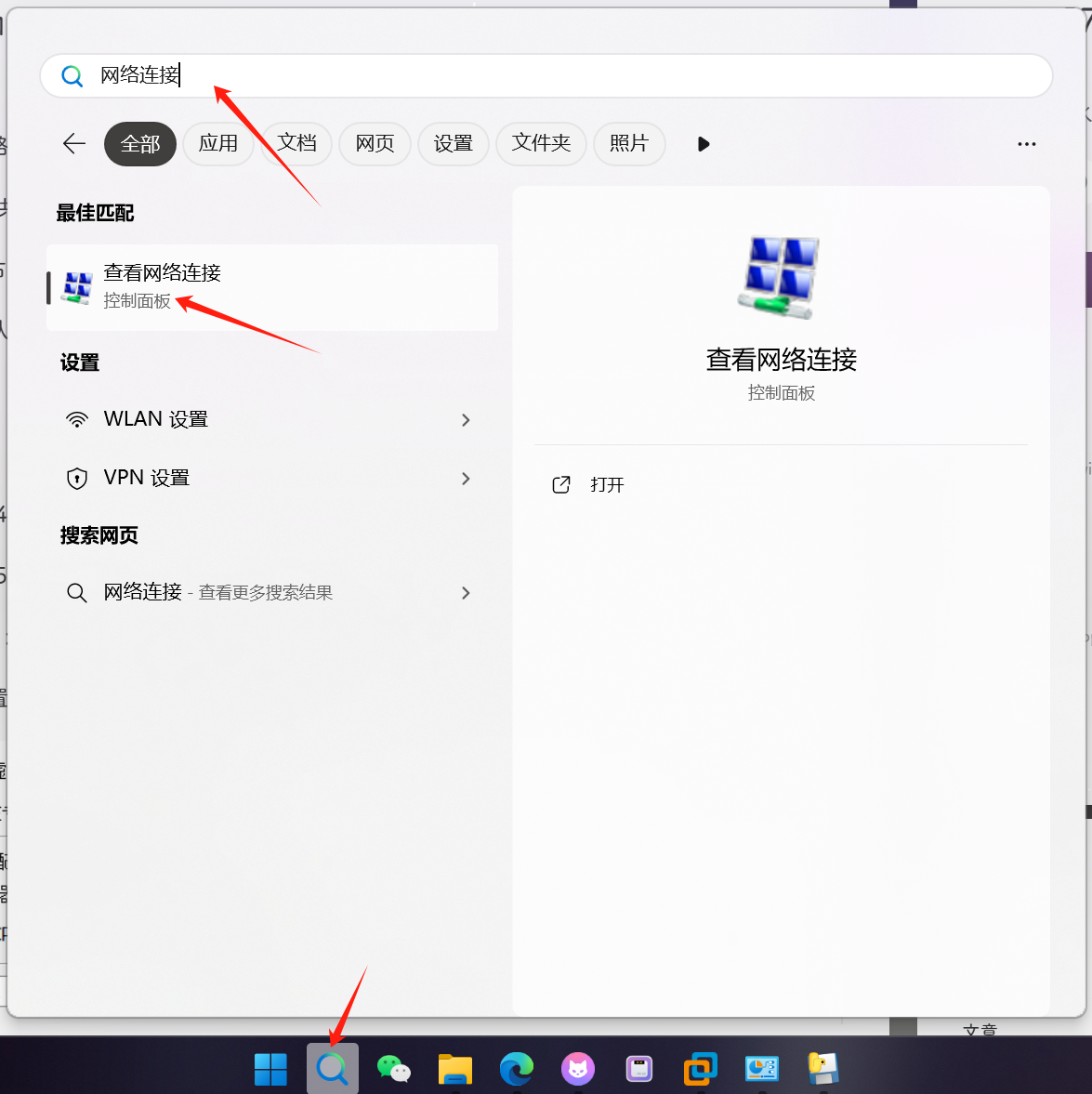
共享:已有的网络开启共享
右键-状态-属性-共享-vmnet8
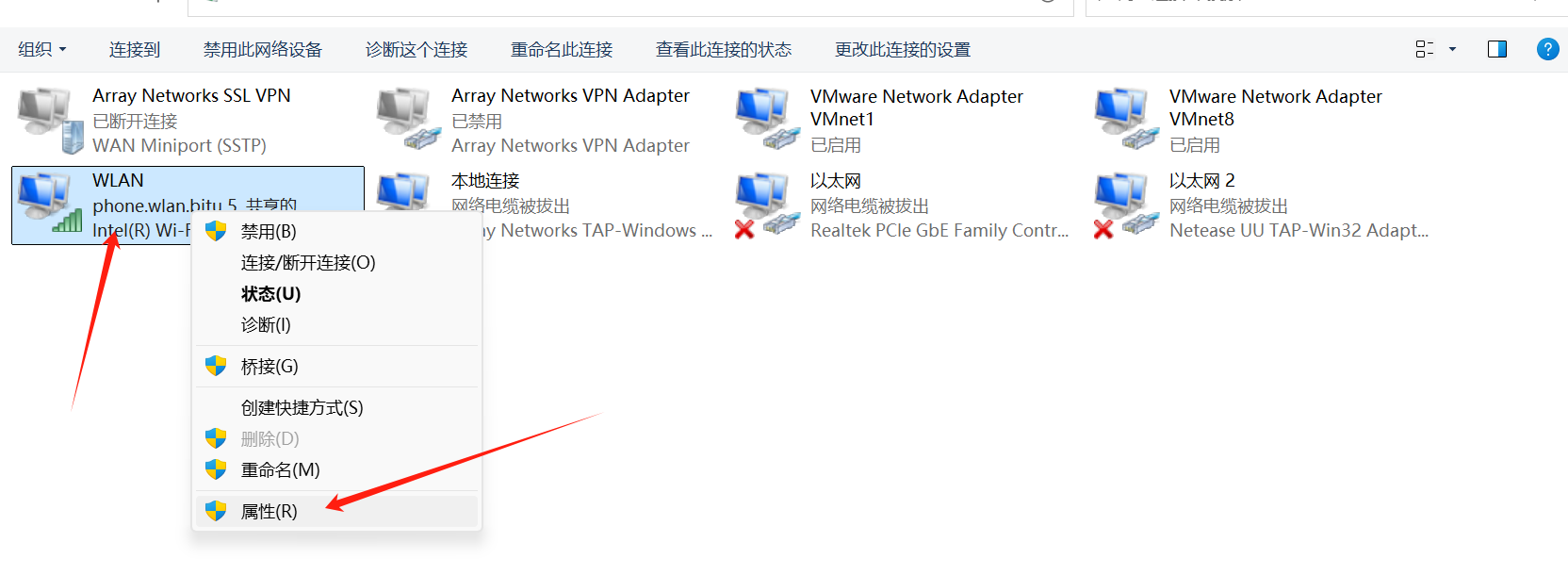
确定vmnet8 ip:右键-状态-详细信息
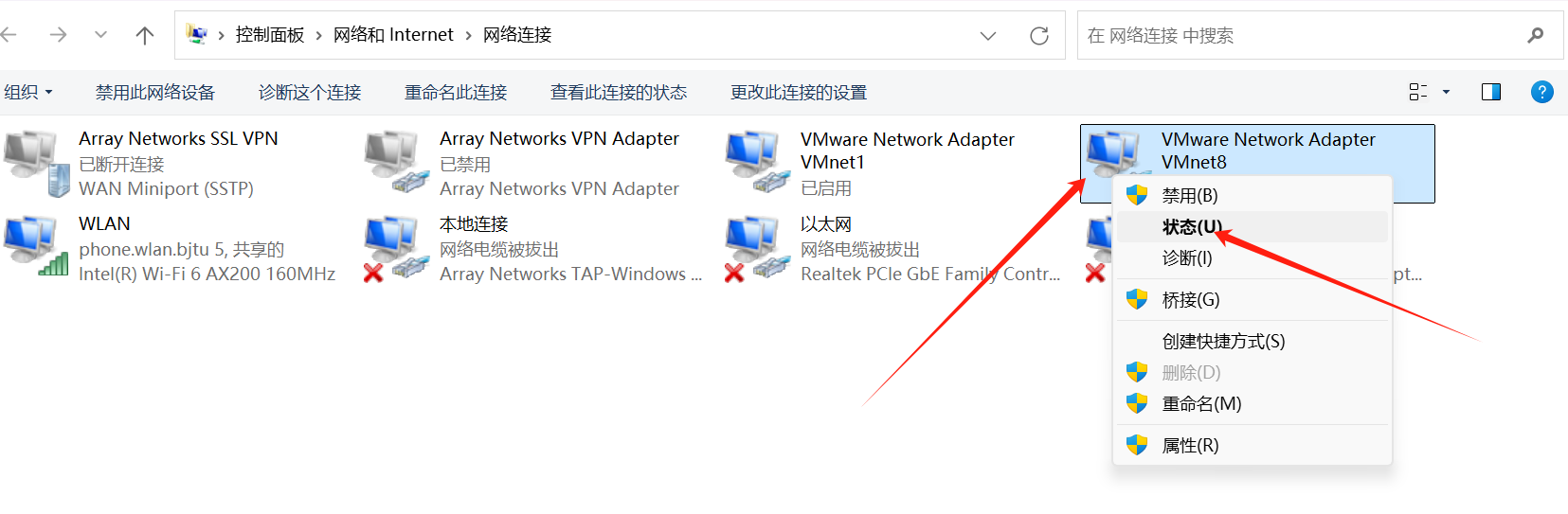
记录下ipv4和默认网关、DNS、子网掩码等,我的如下:
192.168.137.1
192.168.137.2
114.114.114.114
255.255.255.255
wmware中左上角:编辑-虚拟网络编辑器-更改设置(右下角)
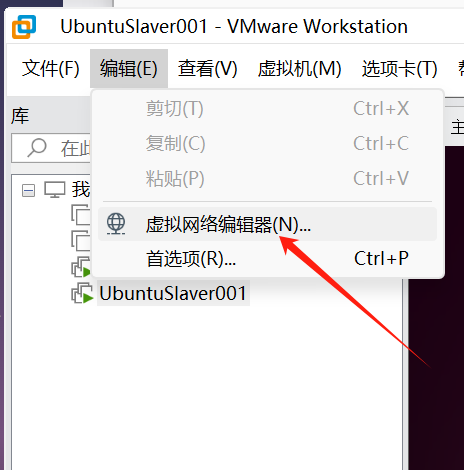
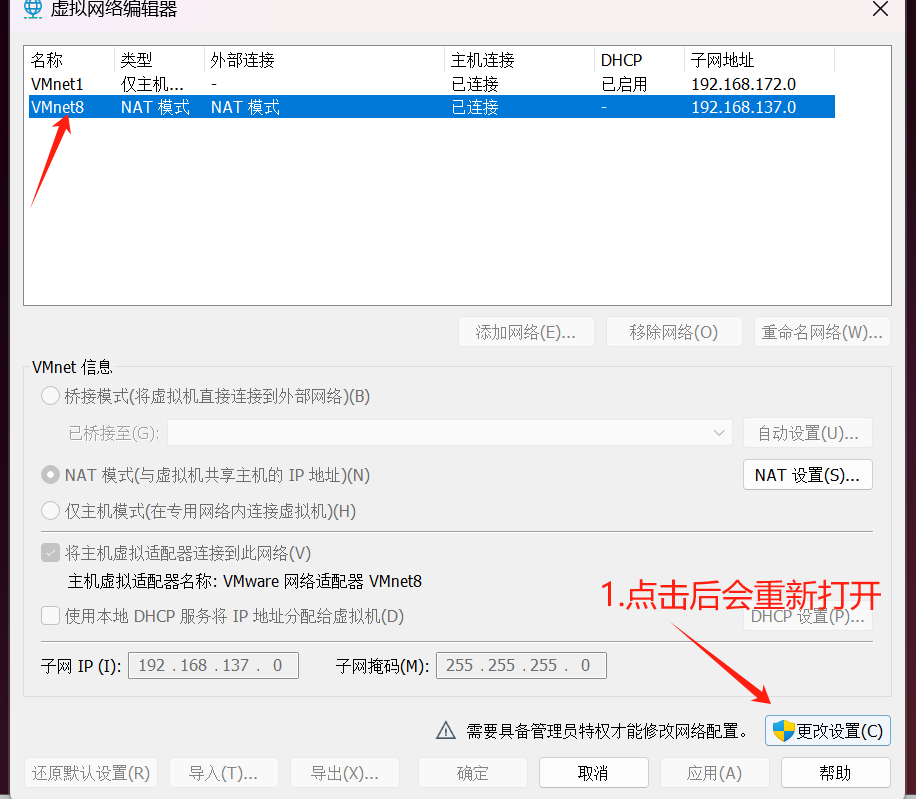
选中VMnet8 设置nat模式,关闭DHCP,设置子网ip
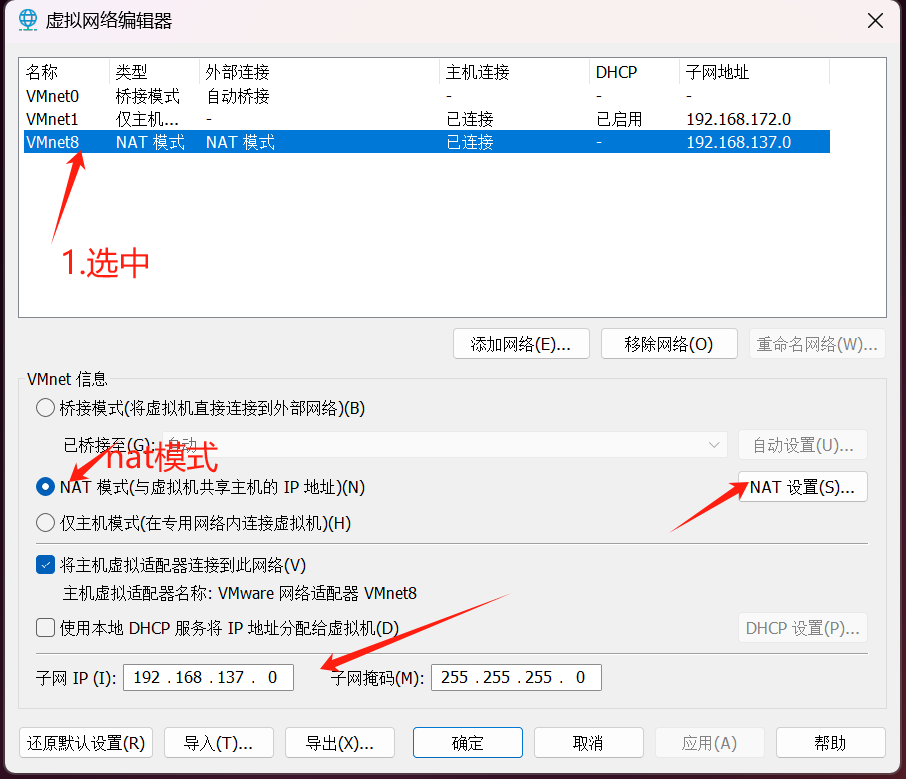
192.168.137.0 (最后一位写0)
进入net设置写入网关(前面记录的网关)
在库中右键ubuntu打开设置-网络适配器-自定义-VMNet8
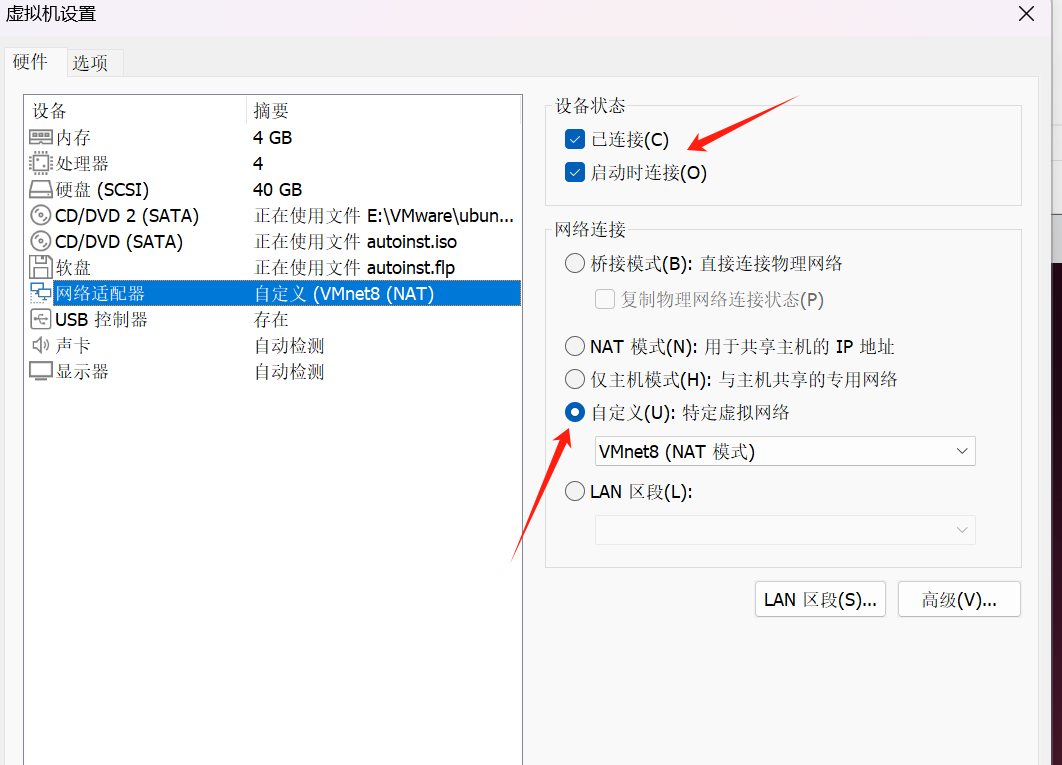
2.虚拟机中
进入虚拟机-Termianl
查看网卡虚拟网卡名称
ip address
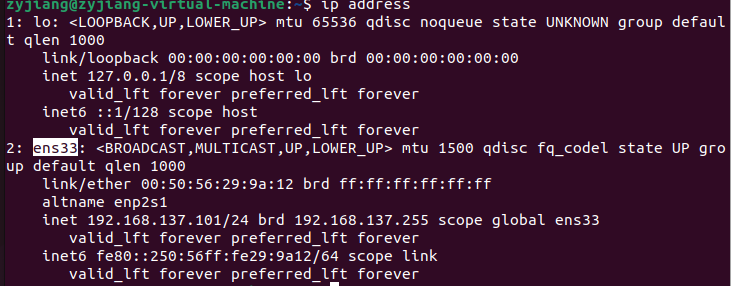
我的是ens33,如果你的不是,后面代码中的这个全部替换成你自己的网卡名字。
配置信息
sudo vi /etc/netplan/01-network-manager-all.yamli 进入输入模式,复制下面代码,完全覆盖(shift+insert粘贴)
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: false
addresses: [ 192.168.137.101/24 ]
routes:
- to: default
via: 192.168.137.2
nameservers:
addresses: [8.8.8.8, 8.8.4.4]保存退出
esc :wq
应用
sudo netplan --debug apply输入ip address查看ip是否成功配置
ssh
安装ssh
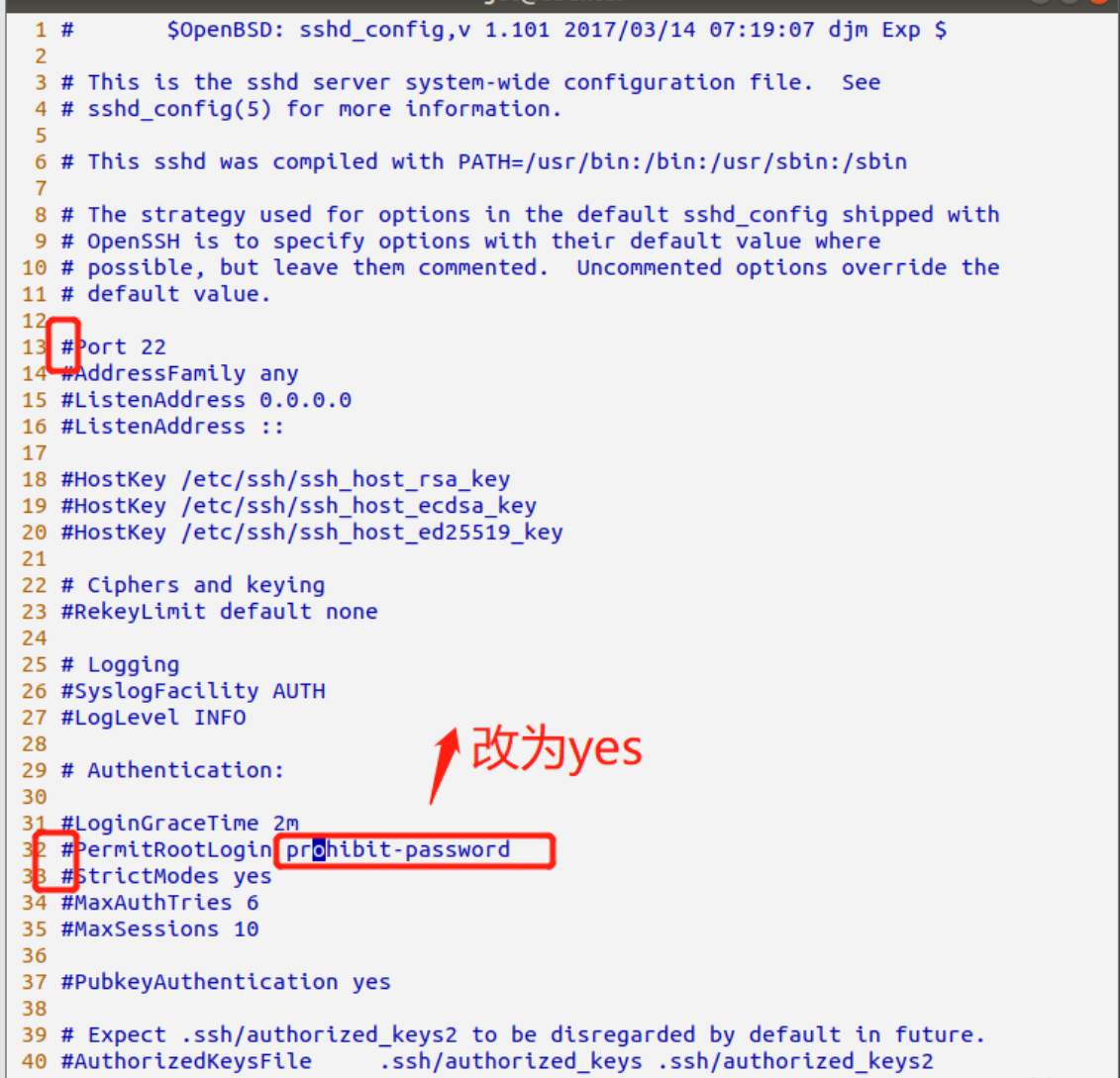
sudo apt install openssh-server配置ssh
sudo vi /etc/ssh/sshd_config去掉下图圈起来得“#”号,将prohibit-password改为yes。如果不该为yes,虚拟机是不允许root用户登录的。
改好之后:wq保存
设置ssh的root用户登入密码
sudo passwd root重启ssh服务
sudo service ssh restart修改主机名
sudo vim /etc/hostname输入i进入修改模式,修改为Master后保存退出esc :wq
重启生效
reboot注:如果你觉得crtlcv更好用,到这你就可以在物理机的cmd上使用ssh连接master主机了.
ssh root@Master
或者
ssh root@192.168.137.102建议不要使用root用户,后面就知道了
推荐使用自己的用户
提前为后续克隆准备
命名为 Master、Slave001 Slave002 Slave003
让其ip分别为102,103,104,105
sudo vi /etc/hosts粘贴新增以下内容:
192.168.137.102 Master
192.168.137.103 Slave001
192.168.137.104 Slave002
192.168.137.105 Slave003Java和hadoop下载
java
sudo apt update
sudo apt install openjdk-17-jdk
sudo apt install openjdk-17-jrehadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz直接下巨慢,建议将hadoop-3.3.6.tar.gz文件拷到虚拟机某个目录,cd到这个目录
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/
mv /opt/hadoop-3.3.6 /opt/hadoop自此,hadoop成功安装到了/opt/hadoop目录下。
java和hadoop环境配置
sudo vi /etc/profile
source /etc/profileJAVA_HOME="/path/to/java/install"
JAVA_HOME="/usr/lib/jvm/java-17-openjdk-amd64"
HADOOP_HOME="/opt/hadoop"
CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
HADOOP_INSTALL=$HADOOP_HOME
HADOOP_MAPRED_HOME=$HADOOP_HOME
HADOOP_COMMON_HOME=$HADOOP_HOME
HADOOP_HDFS_HOME=$HADOOP_HOME
YARN_HOME=$HADOOP_HOME
HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
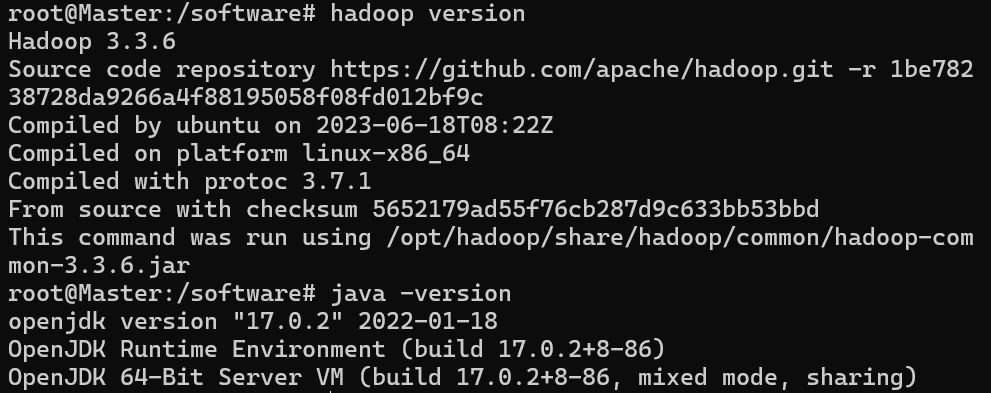
export PATH HADOOP_HOME CLASSPATH请确保hadoop和java配置好,通过如下两命令测试:
java -version
hadoop version成功如下:
进一步配置hadoop
因为无论是Master还是slave,他们都要相同的hadoop配置,因此我们提前配置好再克隆,省的后面一个个配置。
cd $HADOOP_HOME/etc/hadoop/- hadoop-env.sh
sudo vi hadoop-env.sh解除注释,修改如下:
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64jdk17默认不允许匿名函数反射,因此还要修改一个选项
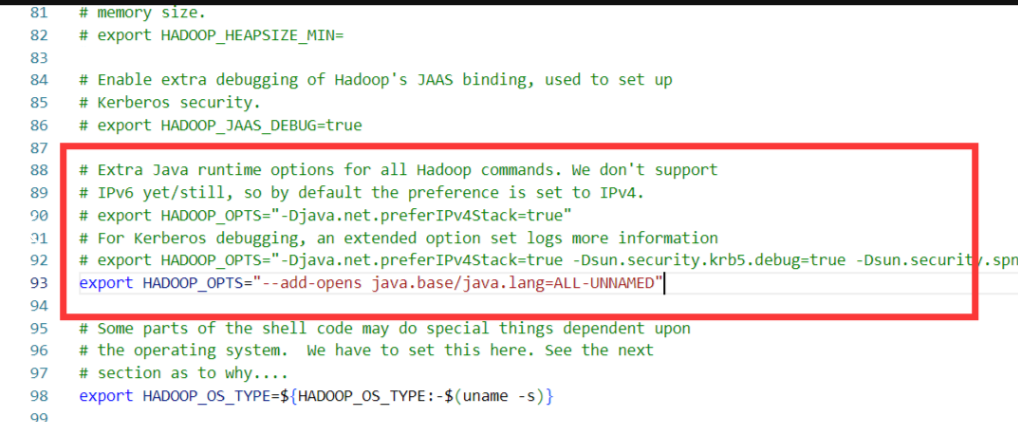
export HADOOP_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"- core-site.xml
sudo vi core-site.xml编辑内容:注意Master是我们之前配置的hosts
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data/tmp</value>
</property>
</configuration>- hdfs-site.xml
sudo vi hdfs-site.xml覆盖配置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/data/datanode</value>
</property>
</configuration>- mapred-site.xml
sudo vi mapred-site.xml覆盖配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>- yarn-site.xml
sudo vi yarn-site.xml覆盖配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 客户端提交作业的端口 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>- workers
sudo vi workers删除原有内容,写入配置
slave001
slave002
slave003- 创建数据目录
mkdir -p /opt/hadoop/data/{tmp,namenode,datanode}克隆slave
关闭Master主机,在wmware中链接克隆出slave001
克隆完成别急着打开。先配置mac地址。
在WMware station左侧库中右键打开克隆的虚拟机slave001的设置:网络适配器-高级-mac地址处-生成-保存。
打开克隆的虚拟机,配置信息中修改ipv4
配置信息
sudo vi /etc/netplan/01-network-manager-all.yamli 进入输入模式,修改ip为103
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: networkd
ethernets:
ens33:
dhcp4: false
addresses: [ 192.168.137.103/24 ]
routes:
- to: default
via: 192.168.137.2
nameservers:
addresses: [8.8.8.8, 8.8.4.4]保存退出
esc :wq
应用
sudo netplan --debug apply输入ip address查看ip是否成功配置.
环境配置完成。
修改主机名
sudo vim /etc/hostname输入i进入修改模式,修改slave001后保存退出esc :wq
同理克隆出slave002 ip 104 ;slave003 ip 105
SSH免密
Hadoop要求主节点(Master)能通过SSH无密码登录所有从节点(slaves)。
步骤 1:生成SSH密钥对(所有节点)
ssh-keygen -t rsa # 一直按回车,默认不设密码步骤 2:将公钥分发到所有节点(包括自身)
在Master节点执行:(使用yes使用密码登入以上传密钥)
bash# 将Master的公钥复制到自身 ssh-copy-id master # 将Master的公钥复制到Slave1 ssh-copy-id slave001 # 将Master的公钥复制到Slave2 ssh-copy-id slave002 # 将Master的公钥复制到Slave3 ssh-copy-id slave003验证:从Master节点执行
ssh slave001,确认无需密码即可登录。
如果报错,可能需要删除旧的密钥
ssh-keygen -R "slave001"注意:强烈建议使用自己的用户名而不是root
配置分发
再次同步Master的hadoop配置到slave上
scp -r /opt/hadoop slave001:/opt/
scp -r /opt/hadoop slave002:/opt/
scp -r /opt/hadoop slave003:/opt/
scp /opt/hadoop/etc/hadoop/yarn-site.xml slave001:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/yarn-site.xml slave002:/opt/hadoop/etc/hadoop/
scp /opt/hadoop/etc/hadoop/yarn-site.xml slave003:/opt/hadoop/etc/hadoop/启动 Hadoop 集群
(1) 首次格式化 HDFS(仅在 Master 执行一次)
hdfs namenode -format(2) 启动 HDFS 和 YARN
start-dfs.sh # 启动 HDFS
start-yarn.sh # 启动 YARN如果报错"尝试以root用户操作",是因为root用户执行命令时不会再环境变量中带上自己的身份信息。可以在每次执行前执行如下代码:(不推荐)
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root或者切换到其他用户再执行一次ssh免密操作(推荐)
进入三个slave主机和master主机中执行:用户名替换为自己的用户名
sudo chown -R zyjiang:zyjiang /opt/hadoop
sudo mkdir -p /opt/hadoop/{logs,pids}
sudo chmod 755 /opt/hadoop/logs(3) 验证进程
Master 节点:执行
start-yarn.sh,应看到:9570 ResourceManager 9354 SecondaryNameNode 9915 Jps 9119 NameNodeSlave 节点:执行
jps,应看到:DataNode NodeManager
验证集群状态
(1) 查看 HDFS 节点
hdfs dfsadmin -report(2) 访问 Web 界面
- HDFS NameNode:
http://master:9870 - YARN ResourceManager:
http://master:8088
(3) 运行测试作业
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar pi 2 46. 停止集群
stop-yarn.sh
stop-dfs.sh嫌麻烦可以
start-all.sh
stop-all.shmapreduce实验
1. 安装 Python 3
打开终端,执行以下命令更新软件包列表并安装 Python 3:
sudo apt update sudo apt install python3验证安装:
python3 --version2. 创建并编辑 test.txt 创建工作目录并进入:
mkdir -p ~/workspace cd ~/workspace使用文本编辑器创建 test.txt 并输入内容
(例如每行写一些英文单词,用空格分隔):
nano test.txt输入完成后,按 Ctrl + X,输入 Y 确认保存,按 Enter 确认文件名。
3. 上传 test.txt 到 Hadoop 集群
确保 Hadoop 已配置且服务正常运行(若未启动,先执行 $HADOOP_HOME/sbin/start-dfs.sh 启动 HDFS)。 创建 HDFS 输入目录并上传文件:
hdfs dfs -mkdir -p /input hdfs dfs -put test.txt /input4. 编写并保存 wordcount.py
将以下代码保存为 wordcount.py:
# coding:utf-8 from mrjob.job
import MRJob class WordCount(MRJob):
def mapper(self, key, value):
words = str(value).split(" ")
for word in words:
yield word, 1
def reducer(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
WordCount.run()5. 运行 mrjob 任务
确保 Hadoop 集群服务(HDFS 和 YARN)已启动(执行 $HADOOP_HOME/sbin/start-dfs.sh 和 $HADOOP_HOME/sbin/start-yarn.sh)。 在终端执行:
cd ~/workspace/
python3 wordcount.py -r hadoop hdfs:///input/test.txt -o hdfs:///output-r hadoop:指定在 Hadoop 集群上运行。hdfs:///input/test.txt:HDFS 中输入文件路径。-o hdfs:///output:指定输出目录(输出目录不能存在,需提前确hdfs:///output未创建)。
6. 查看结果
任务执行完成后,查看 HDFS 输出目录中的结果:
hdfs dfs -cat /output/part-00000sudo scp /opt/hadoop/etc/hadoop/* slave001:/opt/hadoop/etc/hadoop
sudo scp /opt/hadoop/etc/hadoop/* slave002:/opt/hadoop/etc/hadoop
sudo scp /opt/hadoop/etc/hadoop/* slave003:/opt/hadoop/etc/hadoopsudo apt install openjdk-8-jdk
sudo update-alternatives --config java
ls /usr/lib/jvm | grep java-8-openjdk
sta
vi ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bashrc
echo $JAVA_HOME
sudo update-alternatives --config javahive安装
安装在/opt/apache-hive-4.0.1-bin
配置
我的建议是:改好了直接cp进去
cp ~/hive-site.xml /opt/apache-hive-4.0.1-bin/conf/hive-site.xml<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ========== 元存储配置 ========== -->
<!-- MySQL 连接配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mariadb://master:3306/hive_metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.mariadb.jdbc.Driver</value>
</property>
<!-- 数据库用户名和密码 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>zyjiang</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>psd</value>
</property>
<!-- ========== Hive 运行配置 ========== -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<!-- 其他重要配置 -->
<!-- hiveserver2的高可用参数,如果不开会导致了开启tez session导致hiveserver2无法启动 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
<!--解决Error initializing notification event poll问题-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>配置修改
vi /etc/profile新增
export HIVE_HOME=/opt/apache-hive-4.0.1-bin
export HIVE_CLASSPATH=$HIVE_HOME/lib/*:$HIVE_HOME/confhiveserver2配置
- hadoop-env.sh
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh(如果是jdk17)新增如下内容:
export HADOOP_CLIENT_OPTS="--add-opens java.base/java.net=ALL-UNNAMED --add-opens java.base/java.nio=ALL-UNNAMED --add-opens java.base/java.lang.reflect=ALL-UNNAMED $HADOOP_CLIENT_OPTS"修改hive-env.sh
# export HIVE_AUX_JARS_PATH=
export HADOOP_HOME=/opt/hadoop # 根据实际 Hadoop 安装路径修改
export HIVE_CONF_DIR=/opt/apache-hive-4.0.1-bin/conf
export HIVE_AUX_JARS_PATH=$HADOOP_HOME/share/hadoop/common/lib:$HADOOP_HOME/share/hadoop/hdfs/lib
# 如果jdk17需要下面配置
export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.net=ALL-UNNAMED"
export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/java.lang=ALL-UNNAMED"
export HADOOP_OPTS="$HADOOP_OPTS --add-opens=java.base/sun.net.www.protocol.http=ALL-UNNAMED"
export HADOOP_CLIENT_OPTS="--add-opens java.base/java.net=ALL-UNNAMED $HADOOP_CLIENT_OPTS"- core-site.xml
vi $HADOOP_HOME/etc/hadoop/core-site.xml新增如下内容:(不然待会连不上)
<property>
<name>hadoop.proxyuser.zyjiang.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.zyjiang.groups</name>
<value>*</value>
</property>分发
scp $HADOOP_HOME/etc/hadoop/core-site.xml slave001:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/core-site.xml slave002:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/core-site.xml slave003:$HADOOP_HOME/etc/hadoop/端口防火墙
sudo ufw allow 10000
sudo ufw reload初始化 Hive 元数据库
schematool -dbType mysql -initSchema停止服务
pkill -f HiveServer2
pkill -f HiveMetaStore启动 HiveServer2 服务
# 后台启动
hive --service metastore > ~/logs/metastore.log 2>&1 &
hive --service hiveserver2 > ~/logs/hiveserver2.log 2>&1 &查看log
vi /tmp/zyjiang/hive.loggrep "HADOOP_OPTS" ~/logs/hiveserver2.log如果想在控制台看输出,使用下面的代替上面
hive --service metastore
hive --service hiveserver2验证端口监听
netstat -tuln | grep 10000检查进程
jps
ps -ef | grep "[h]iveserver2"连接 Beeline
beeline -u "jdbc:hive2://master:10000" -n zyjiang验证
beeline
!connect jdbc:hive2://master:10000;beeline -u "jdbc:hive2://master:10000" -n zyjianghive实验:
创建Hive表,将本地csv文件导入到Hive表格,执行HiveQL查询(30分) 上传文件到hdfs,创建Hive表(5分) 将本地csv文件导入到Hive表格(10分) 执行HiveQL查询——根据csv数据筛选记录超过2次的常旅客(5分)、分小时进出站量(5分)、分小时OD量(5分)
根据筛选结果,借助python等进行可视化并分析(10分 )
数据准备
将目标数据放入~/workspace/hivedata/文件夹中,上传至hdfs
hdfs dfs -mkdir /input/afc/
hdfs dfs -mkdir /input/afc/normal
hdfs dfs -mkdir /input/afc/peak
hdfs dfs -put ~/workspace/hivedata/AFC*.csv /input/afc/normal
hdfs dfs -put ~/workspace/hivedata/peak_hours_AFC*.csv /input/afc/peak进入web端口检查一下
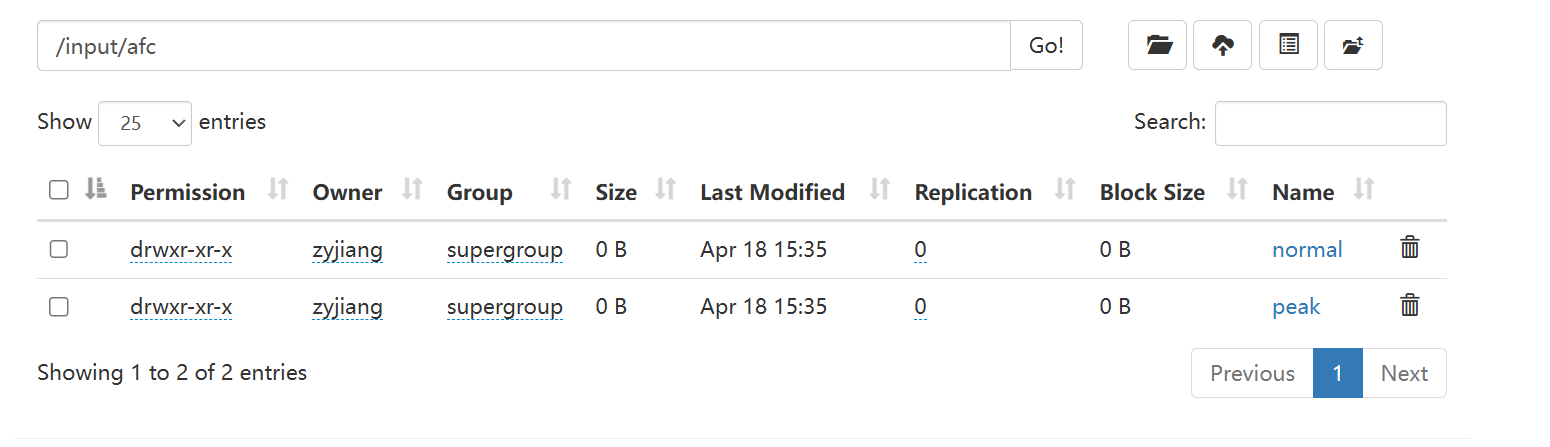
成功上传。
hive建立表
CREATE DATABASE IF NOT EXISTS afc;
SHOW DATABASES;
USE afc;
CREATE EXTERNAL TABLE afc_peak (
`date` STRING,
passenger_id BIGINT,
ticket_type INT,
entry_station_id INT,
entry_timestamp STRING,
entry_line_id INT,
exit_station_id INT,
exit_timestamp STRING,
exit_line_id INT,
peak_type STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/input/afc/peak/'
TBLPROPERTIES ('skip.header.line.count'='1');
CREATE EXTERNAL TABLE afc_normal (
`date` STRING,
passenger_id BIGINT,
ticket_type INT,
entry_station_id INT,
entry_timestamp STRING,
entry_line_id INT,
exit_station_id INT,
exit_timestamp STRING,
exit_line_id INT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/input/afc/normal/'
TBLPROPERTIES ('skip.header.line.count'='1');
SHOW TABLES;此时我们可以看到:
+-------------+
| tab_name |
+-------------+
| afc_normal |
| afc_peak |
+-------------+执行HiveQL查询
连接 Beeline
hive --service metastore > ~/logs/metastore.log 2>&1 &
hive --service hiveserver2 > ~/logs/hiveserver2.log 2>&1 &
beeline -u "jdbc:hive2://master:10000" -n zyjiang查询1:筛选记录超过2次的常旅客
SELECT passenger_id, COUNT(*) AS trip_count
FROM afc_normal
GROUP BY passenger_id
HAVING trip_count > 2;查询2:分小时进出站量
SELECT hour, SUM(entry_count) AS total_entry, SUM(exit_count) AS total_exit
FROM (
SELECT
date_format(
from_unixtime(
unix_timestamp(
regexp_replace(entry_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
)
),
'HH'
) AS hour,
1 AS entry_count,
0 AS exit_count
FROM afc_normal
WHERE
unix_timestamp(
regexp_replace(entry_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
) IS NOT NULL
UNION ALL
SELECT
date_format(
from_unixtime(
unix_timestamp(
regexp_replace(exit_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
)
),
'HH'
) AS hour,
0,
1
FROM afc_normal
WHERE
unix_timestamp(
regexp_replace(exit_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
) IS NOT NULL
) combined
GROUP BY hour
ORDER BY hour;查询3:分小时OD量(按进站时间统计)
SELECT
date_format(
from_unixtime(
unix_timestamp(
regexp_replace(entry_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
)
),
'HH'
) AS hour,
entry_station_id,
exit_station_id,
COUNT(*) AS od_count
FROM afc_normal
WHERE
unix_timestamp(
regexp_replace(entry_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
) IS NOT NULL
GROUP BY
date_format(
from_unixtime(
unix_timestamp(
regexp_replace(entry_timestamp, '^([0-9]{4}/[0-9]{2}/[0-9]{2}) ([0-9]):', '$1 0$2:'),
'yyyy/MM/dd HH:mm:ss'
)
),
'HH'
),
entry_station_id,
exit_station_id
ORDER BY
hour,
entry_station_id,
exit_station_id;查询结果大致如下:
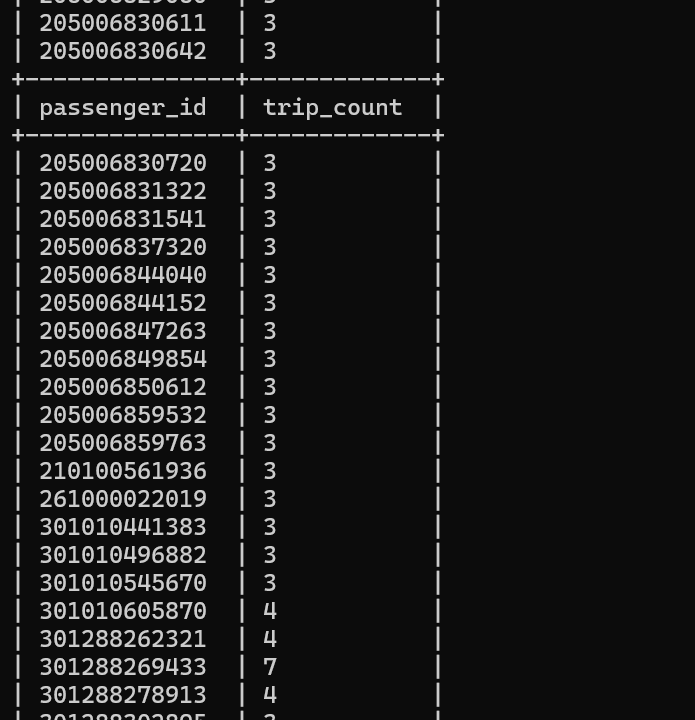
将结果东西保存代码
1 筛选记录超过2次的常旅客(保存到/output/1)
-- 执行查询并导出到HDFS目录
INSERT OVERWRITE DIRECTORY '/output/1'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT
passenger_id,
COUNT(*) AS trip_count
FROM
afc_normal
GROUP BY
passenger_id
HAVING
trip_count > 2;2 分小时进出站量(保存到/output/2)
-- 执行查询并导出到HDFS目录
INSERT OVERWRITE DIRECTORY '/output/2'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT
hour,
SUM(entry_count) AS total_entry,
SUM(exit_count) AS total_exit
FROM (
SELECT
SUBSTR(entry_timestamp, 12, 2) AS hour,
1 AS entry_count,
0 AS exit_count
FROM
afc_normal
UNION ALL
SELECT
SUBSTR(exit_timestamp, 12, 2) AS hour,
0,
1
FROM
afc_normal
) combined
GROUP BY
hour
ORDER BY
hour;3 分小时OD量(按进站时间统计,保存到/output/3)
-- 执行查询并导出到HDFS目录
INSERT OVERWRITE DIRECTORY '/output/3'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT
SUBSTR(entry_timestamp, 12, 2) AS hour,
entry_station_id,
exit_station_id,
COUNT(*) AS od_count
FROM
afc_normal
GROUP BY
SUBSTR(entry_timestamp, 12, 2),
entry_station_id,
exit_station_id;验证HDFS输出
hdfs dfs -ls /output/1
hdfs dfs -ls /output/2
hdfs dfs -ls /output/3直接在网页端查看更加方便
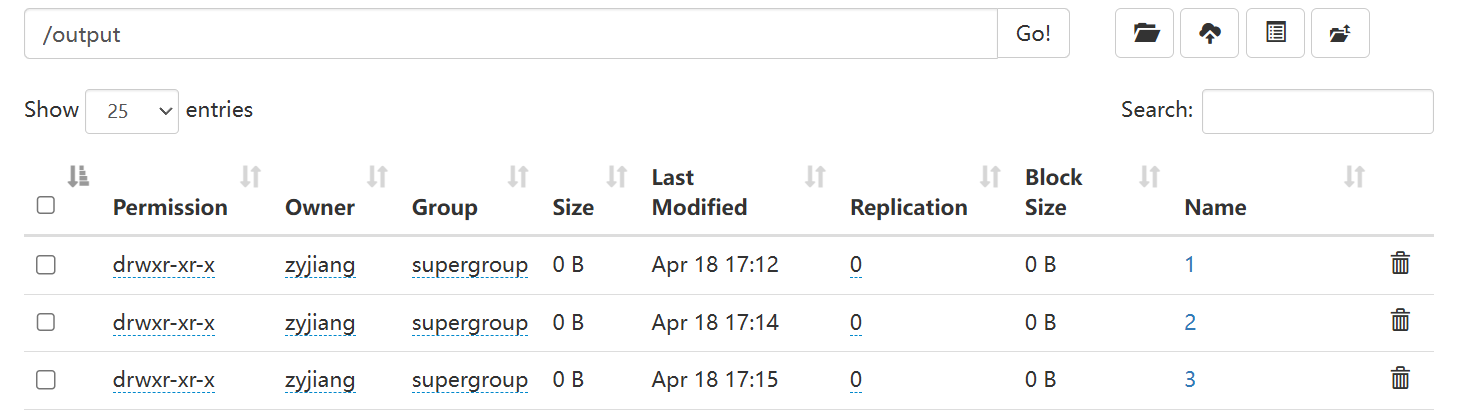
可以看到结果
如此,我们可以直接使用python直接连接hive的sql读取数据并可视化处理,输出图像。
安装相应的包
sudo apt-get install libsasl2-dev python3-dev
pip install pyhive[hive] pandas matplotlib seaborn在~/workspace下创建py文件
# 导入依赖
from pyhive import hive
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import os
# 配置Hive连接
HIVE_HOST = "master" # 你的Hive服务器地址
HIVE_PORT = 10000 # Hive Thrift端口
HIVE_USER = "zyjiang" # 你的用户名
# 创建输出目录
os.makedirs("output_images", exist_ok=True)
# 连接Hive
def connect_hive():
conn = hive.Connection(
host=HIVE_HOST,
port=HIVE_PORT,
username=HIVE_USER
)
return conn
# 执行查询并返回DataFrame
def run_query(query):
conn = connect_hive()
df = pd.read_sql(query, conn)
conn.close()
return df
# ------------------------------
# 查询1:筛选记录超过2次的常旅客
# ------------------------------
query1 = """
SELECT passenger_id, COUNT(*) AS trip_count
FROM afc_normal
GROUP BY passenger_id
HAVING trip_count > 2
ORDER BY trip_count DESC
"""
df1 = run_query(query1)
# 可视化:Top 10常旅客
plt.figure(figsize=(10, 6))
sns.barplot(data=df1.head(10), x="passenger_id", y="trip_count", palette="viridis")
plt.title("Top 10 Frequent Travelers (Trips > 2)")
plt.xlabel("Passenger ID")
plt.ylabel("Trip Count")
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig("output_images/frequent_travelers.png")
plt.close()
# ------------------------------
# 查询2:分小时进出站量
# ------------------------------
query2 = """
SELECT
hour,
SUM(entry_count) AS total_entry,
SUM(exit_count) AS total_exit
FROM (
SELECT SUBSTR(entry_timestamp, 12, 2) AS hour, 1 AS entry_count, 0 AS exit_count
FROM afc_normal
UNION ALL
SELECT SUBSTR(exit_timestamp, 12, 2) AS hour, 0, 1
FROM afc_normal
) combined
GROUP BY hour
ORDER BY hour
"""
df2 = run_query(query2)
# 可视化:分小时进出站折线图
plt.figure(figsize=(12, 6))
plt.plot(df2["hour"], df2["total_entry"], label="Entry", marker="o", linestyle="-")
plt.plot(df2["hour"], df2["total_exit"], label="Exit", marker="x", linestyle="--")
plt.title("Hourly Passenger Flow (Entry vs Exit)")
plt.xlabel("Hour of Day")
plt.ylabel("Count")
plt.legend()
plt.grid(True)
plt.savefig("output_images/hourly_flow.png")
plt.close()
# ------------------------------
# 查询3:分小时OD量(按进站时间统计)
# ------------------------------
query3 = """
SELECT
SUBSTR(entry_timestamp, 12, 2) AS hour,
entry_station_id,
exit_station_id,
COUNT(*) AS od_count
FROM afc_normal
GROUP BY SUBSTR(entry_timestamp, 12, 2), entry_station_id, exit_station_id
ORDER BY hour, od_count DESC
"""
df3 = run_query(query3)
# 可视化:Top 10高频OD对(按小时)
for hour in df3["hour"].unique():
df_hour = df3[df3["hour"] == hour].head(10)
if not df_hour.empty:
plt.figure(figsize=(12, 6))
sns.barplot(data=df_hour, x="od_count", y="entry_station_id", hue="exit_station_id", orient="h")
plt.title(f"Top 10 OD Pairs at Hour {hour}")
plt.xlabel("OD Count")
plt.ylabel("Entry Station ID")
plt.tight_layout()
plt.savefig(f"output_images/od_hour_{hour}.png")
plt.close()